

What is an Orphan Page?
An orphan page is a page on your site that is not linked to by another page.
Finding orphan pages is essential when diagnosing any site architecture issues. Why? Because checking for orphan pages may highlight areas of your site that have no internal links, which would result in a poor distribution of link equity to these pages as well as a bad user experience.
Having orphan pages also means the URLs will more than likely not be found by web crawlers such as Googlebot, or at least massively de-prioritised. It could also mean that pages have been found by Googlebot and are indexed, but a developer or webmaster has not removed the page when it is no longer needed and has instead removed all internal links.
Usually, the second instance will happen when creating temporary pages such as a summer sale or another seasonal page that you want to remove once the event has ended.
Unfortunately, quite often you will find that these pages never actually get removed from the site and instead, depending on the severity of the issue, end up contributing to problems such as index bloat, keyword cannibalisation or just poor internal linking.
There are many ways to find these pages. The process for finding them usually follows the below steps:
- Find all URLs on your site.
- Crawl the site from the home page and find which URLs have internal links pointing to them.
- Look up all the URLs you found against all the URLs you found when crawling.
I have created a spreadsheet template for finding orphaned pages which will be handy when following this process, you can access it by clicking the image below:

Step 1 - Find all URLs on your site
Orphan pages can be quite tricky to find, so It’s important that we find all pages by checking the sitemap, log files and third-party tools if you have access. Let’s kick-start by checking the sitemap.
Method 1 - Check against your sitemap
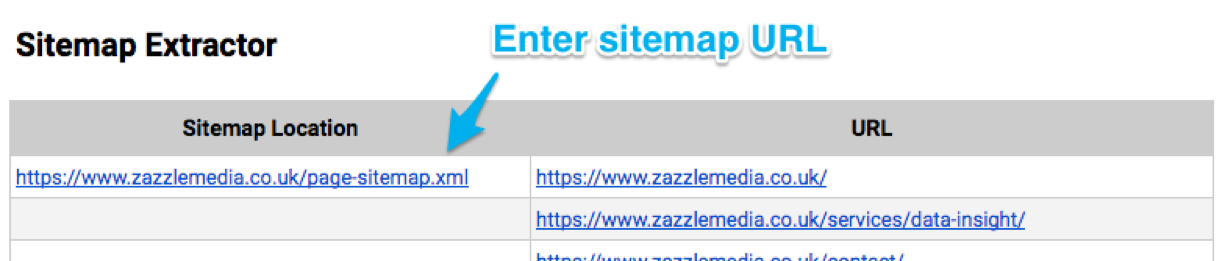
Developers will frequently create sitemaps which contain all URLs that are present in a sites database. This makes sitemaps an ideal location for orphan pages to be hiding. To extract URLs from your sitemap make a copy of this template by going to File > Make a Copy. Then input the URL of your sitemap in the 'Sitemap Extractor' tab under the 'Sitemap Location' column.
Method 2 - Use your log files
If you think you have pages that are indexed by Google and have no internal links to them, your server log files may highlight them, as Google goes back to re-crawl the URL to see if anything has changed. To do this, you are going to need to get your log files off your server (or ask your developer for them). Once I have them, I usually just import the logs into Screaming Frog's Log File Analyser then you can go to the URL's tab, filter for HTML, then export.
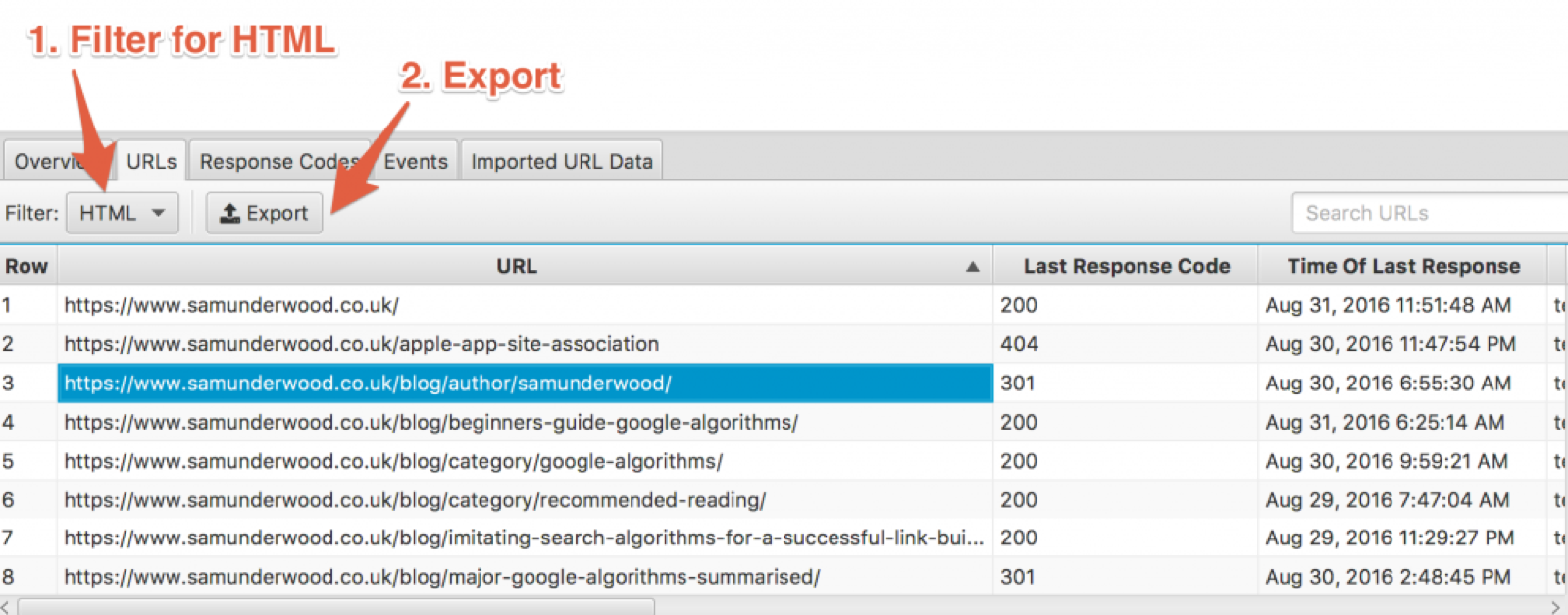
Next, open up the CSV file and filter the table to only show pages with a 200 status code. Copy the URLs from the 'URL' column of your export over to the 'Log Files Export' sheet in the previously mentioned tool here.

Method 3 - Check Google Analytics
Google Analytics is another source for finding orphan pages. You could potentially be getting referral, paid, direct or organic traffic to these URLs. An export of all pages from Analytics may highlight some extras that other methods might not have done.
Go into Google Analytics and head to the Behaviour > Site Content > All Pages section. Change the date range to over the past three to six months, then export all the pages.
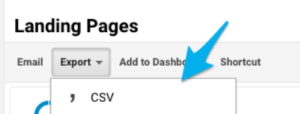
After doing this, you may want to crawl all the URLs from the export, using something such as Screaming Frog to make sure they all return 200 status codes and are still active on the site.
Method 4 - Backlink reports
Another way to find all pages on your site is by checking your backlink profile. To do this you will need to grab an export from your backlink tool of choice. We recommend either Ahrefs or Majestic as they currently have the biggest link databases around. Here's how to get these URLs out of both tools:
Exporting linked to URLs from Ahrefs
1. Login to Ahrefs and then to the 'Site Explorer' tool. Enter your domain name and search.
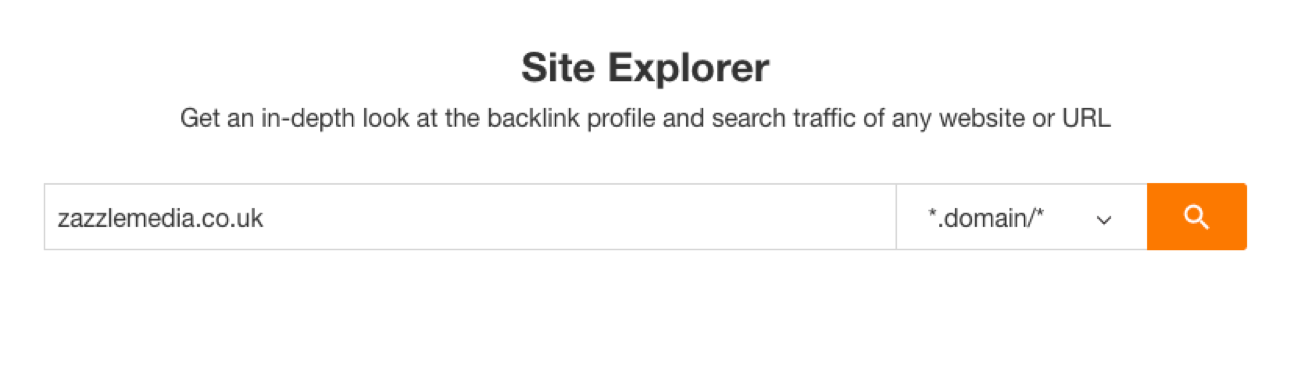 2. Go to the 'Best By Links' page.
2. Go to the 'Best By Links' page.
3. Export all URLs.

4. Open the export in Excel and filter the results for URLs with a 200 response code only.
5. Add these URLs to the 'Backlink Export' sheet in the copied spreadsheet.
Exporting linked to URLs from Majestic
1. Login to Majestic and search for your domain.
2. Go to the 'Pages' page.

3. Export all URLs.
 4. Open the export in Excel and filter for all URLs with a 200 response code, marked as 'DownloadedSuccessfully' in the 'LastCrawlResult' column.
4. Open the export in Excel and filter for all URLs with a 200 response code, marked as 'DownloadedSuccessfully' in the 'LastCrawlResult' column.
5. Add these URLs to the 'Backlink Export' sheet in the copied spreadsheet.
Step 2 - Add internal linking data to the spreadsheet
My favourite tool for quickly crawling a site is Screaming Frog. If you don't already have it, it's definitely worth the relatively small annual licensing fee. Simply download the tool and enter the domain you want to crawl and click start.

Once your crawl has finished, filter the results to return HTML only and export the data.
In Excel you can then remove columns that we do not need - you should have just the 'Address', 'Status Code' and 'Inlinks' columns remaining. Once you have done that, filter for 200 status codes.

Copy and paste the data over to the 'Screaming Frog Crawl' sheet in the Google Sheet resource.
Step 3 - Filter to show orphaned pages
Once all the information has been gathered, give the sheet a little bit of time just to merge all the data you have put in and look up which URLs have internal links. Head over to the 'Orphan Page Report' and filter the 'Inlinks' column to show any orphaned results.
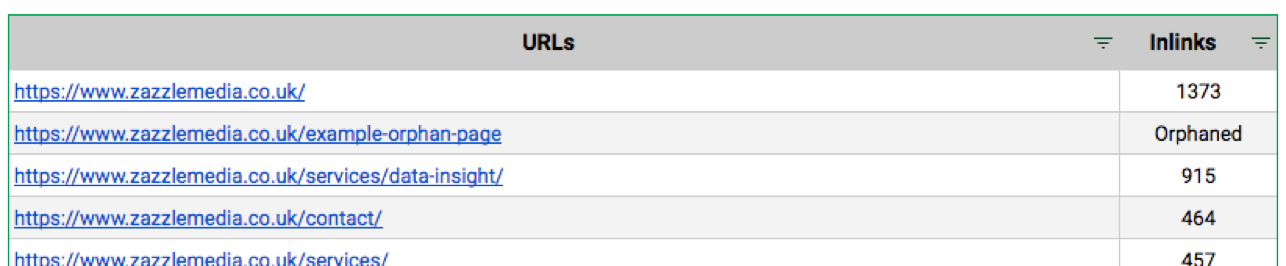
How does finding orphaned pages help?
The end result of doing all this and making use of this spreadsheet is that you can now easily do the following things:
- Find old URLs that may be contributing to index bloat issues.
- Highlight any URLs that may have a low number of internal links pointing to them.
- Remove old pages from your site that have had their internal links removed, but still exist on the site.
Download the spreadsheet template by clicking the button below.
Stay in touch with the Zazzle Media family
Sign up for our monthly newsletter and follow us on social media for the latest news.



