

If you’ve ever been unlucky enough to have been faced with a major keyword cannibalisation issue, you’ll sympathise with us when we say how much trouble it can cause if left alone for too long.
Keyword cannibalisation is often a mistake and the result of overlooking content scale and velocity.
It occurs when multiple pages try to compete for a single keyword. This often leads to crawlers being unable to distinguish which page is most relevant for any particular query.
The sure fire way to prevent this from happening is incredibly in-depth keyword research and content planning, supported by a strong and robust site architecture. However, it would shock you how often these crucial factors are overlooked in the early stages of site development.
Victims of this regular phenomenon, can expect to see keywords drop in-and-out of the index on, potentially, a daily or even an hourly basis.
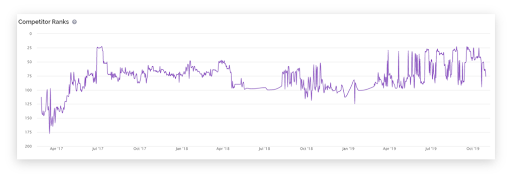
What impact can keyword cannibalisation have?
Before you can begin identifying if you have an issue on your site, you need to know where to look.
Here are some of the more common identifiers.
Very turbulent rankings
The more your keywords ‘flip-flop’ between positions, the less potential your website has of securing a presence in the SERPs.
If this happens at scale (hundreds, even thousands of keywords), you could suffer from an algorithmic filter.
This filter will cause Google’s algorithms to inherently limit your site’s ability to rank for certain queries based on low quality and inconsistent relevancy. It’ll appear as if you’ve been hit by a penalty, but, without warning or notification.
Drops in revenue
A drop in revenue is a very likely subsequence of a serious cannibalisation issue. The less time your ‘money pages’ spend at the top of search engines, the bigger impact you’ll see on your conversion rate (CvR).
Limited user engagement
The most common issue is that users will begin interacting with the wrong pages (i.e., the page you don’t want to rank). And, if this doesn’t align with the initial intent of the searcher, you’re likely to suffer from a drop in CTR.
Whether Google admit it openly or not, we’ll tell you for free that an impacted CTR will wreak havoc on your rankings.
The process of identifying keyword cannibalisation
To keep things simple, we’re going to focus on addressing single-domain cannibalisation; where multiple areas of a site are competing for the same terms.
We’ll do this by utilising page titles, headers and, meta descriptions.
This will give us a very quick overview of how serious the issue is before we begin including performance metrics and digging deeper into the site.
Setting up your crawl
The first step in identifying keyword cannibalisation is to crawl your site. We’re big fans of Screaming Frog but, use a crawler that you feel comfortable with.
Depending on the size of your site, this could take some time. Make a tea or finish that blog post you’re supposed to be writing whilst you wait.
Our go-to solution to speed up the crawl, as much as we can, is to begin excluding subfolders we want kept out of the crawl. Using RegEx, we can quickly prevent folders such as /wp-content/ or /uploads/ being included in our crawl.
RegEx (regular expression) is a way to describe a search pattern. It’s most commonly used application (at least in the SEO world) is in the Robots.txt. It’s our way of using a wildcard in URL strings to prevent crawlers from anything after our defined wildcard (a wildcard just means anything after * needs to be excluded).
For example, if we know an eCommerce store has thousands of images and scripts in /media/, we’d exclude that subfolder in Screaming Frog like this:
https://www.example.com/media/.*
The asterisk tells the crawlers to ignore anything that comes after the /media/ subfolder.
If you’re unsure on RegEx or excluding directories from your crawl, check out Screaming Frog’s Web Scraper Guide.
Once your crawl has finished, you need to begin cleaning your data in Excel. The raw output from Screaming Frog will include non-indexable URLs, image files, script files etc., all of which have no value for this task.
By filtering and deleting rows, we’ll begin cleaning our data set so we focus on URLs that are actually influencing cannibalisation.
The URL output needs to:
- Exclude non-indexable URLs
- Exclude images or script files
- Exclude anything with a status code other than 200
Now, you should have a full list of only indexable URLs.
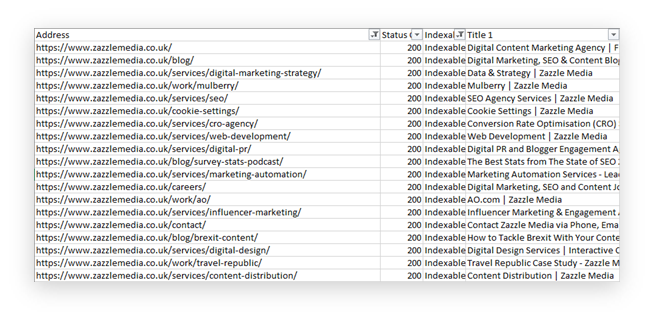
Take the title column and put this into a separate Excel tab. We’re going to use this to count the number of pages which share the same titles. This is a very simple way to find an overlap in keyword targeting.
Dedupe your list of titles in this tab.
Using countif, we’re going to find out how many times a unique title appears in the original dataset.
The ‘countif’ function will search a range of data based on a criteria which we set. In this instance, we’re going to be searching the page title (our criteria) column (our range) to find the occurence of individual page titles.
It will then return a value based on how many times each unique title is found.
The formula:
=COUNTIF(range, criteria)
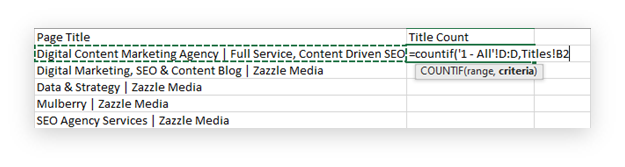
The larger the number, the more serious the cannibalisation issue is.
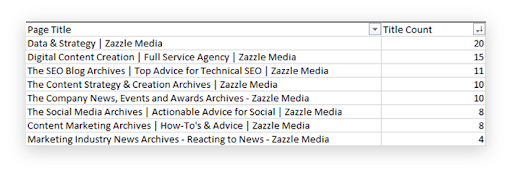
The above table are some example values, based on titles from the Zazzle Media site. They have been created for the purpose of the blog post.
Once we have this number, we know whether we need to dig a little deeper to find performance metrics.
As a side note, please don’t worry about taxonomy pages (tags, categories, blog lister pages).
Aligning with search data
We now understand the severity of the issue. In the original list of only indexable URLs, we’re going to look up the corresponding clicks, impressions and CTR.
We recommend using SuperMetrics for a fuller picture, however, if this isn’t possible, you can export 16 months worth of data into Google Sheets from GSC.
Once you’ve pulled your data, you need to begin aligning performance metrics, with their respective URLs. We do this through the process of a ‘vlookup’.
A vlookup is the process of returning results based on a set criteria from an array of columns. In our example, the criteria we’re basing our search on is the URL. We do this because it’s the common link between the crawl data, and the SuperMetrics data.
Excel will search through the defined array (listed as table_array) and return the desired value based on your criteria (known as lookup_value).
We highly recommend you learn how to use vlookup as you begin analysing data more.
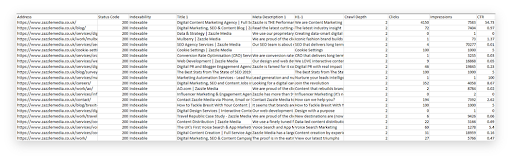
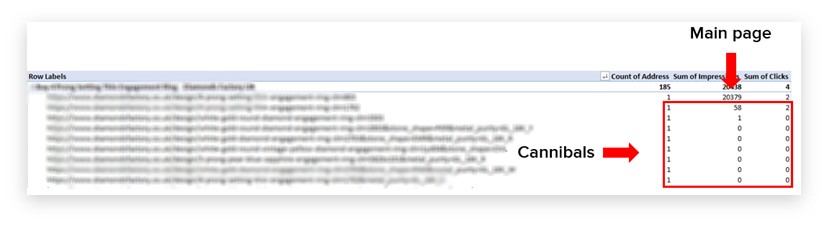
Pivot the data to find the cannibalised pages
Here we are, the juicy stuff.
We’re going to pivot the data to group by page title to see which URLs are associated to each URL.
Insert > Pivot Table > use the following settings:
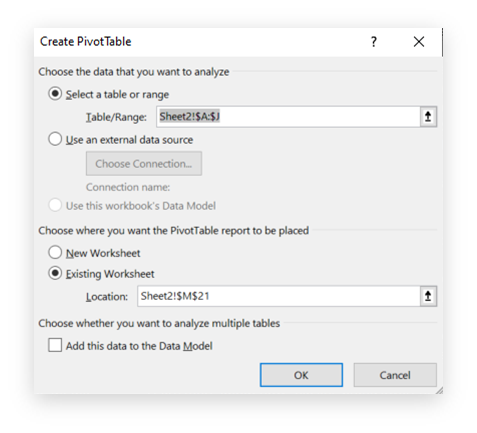
And, for the sake of simplicity, here’s the pivot table setup:
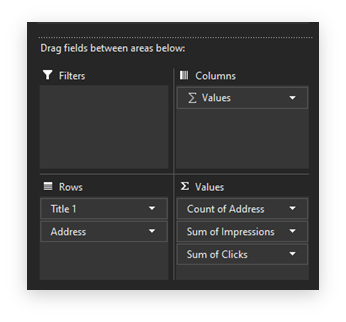
The only addition to the above is the ‘average CTR’ for each URL.
You should now have a table that looks something like this.
How to fix keyword cannibalisation
There are varying ways to resolve this issue; none of which are a single-size fits all, unfortunately. The answer to your cannibalisation issue is often sandwiched between putting the user first and keeping the crawlers happy.
There are a few key considerations you can ask yourself immediately:
- Does this page have any search value?
- If the page doesn’t have search value, is it still helpful for users?
- What happens to my traffic if I remove or redirect?
- Do I have the resources to address this internally?
De-optimise the offending pages
This task could be straightforward but, it doesn’t guarantee that Google will begin to understand your efforts to eliminate relevancy for a term. At the most basic level, you can consider changing page titles and mentions of the keyword.
At a deeper, more reliable level, you could begin reviewing anchor text profiles, internal links and backlinks.
The more heavily a page is associated to a keyword or phrase, the harder it will be to undo the damage. Be prepared for a potentially very labour intensive task.
Redirecting to the authoritative page
There isn’t any harm in simply redirecting crawlers and users to the correct page. The benefit of adding a 301 redirect, is that you pass on any lingering link equity and it’s a simple implementation.
Define the authoritative page as the URL with the most authority, equity and, maturity.
Don’t make the mistake of redirecting old URLs to new URLs, just because they’re new.
Adding canonicals
Canonicals are great for that balance between user and crawler value. A 301 redirect will, obviously, prevent crawlers and users from accessing those pages again. With a canonical, you can keep all pages live and simply direct Google to the page you want to rank.
This can help ease any UX strain caused by removing old pages (think about updating internal links for thousands of new URLs!)
The easiest way to add a canonical to your page is using a line of code inserted into the header. Here’s what the code looks like:

If you’re not familiar with how to include canonicals to your page, we recommend working with your developers for the best solution.
Delete the pages and return a 404
This is the least preferred option as, it’s not great for UX and can be the cause of completely wasting any existing link equity. But, if you’re short on time and developer resource, this can prevent the cannibalised pages from ranking.
Google may still continue to crawl the 404 pages in an attempt to check if the page is ever coming back. If you do notice this, make sure you ensure that any cannibalising-404 pages are kept well out of the index.
Noindexing low-value pages
Not dissimilar to a canonical in the respect of keeping pages with value to the user, adding a noindex tag to pages you don’t want Google to index, is a quick way to prevent these pages from ranking.
This will prevent pages with little-to-no search value from eating up rankings from the priority (or original URL).
To implement a noindex tag, as we did with the canonical directive, we’ll need to add a link of code to the header of the page. Here’s what the code looks like:

Something else you’ll need to consider is crawl budget. If you begin applying the noindex tag to hundreds (possibly thousands of pages), Google may still crawl the internal links on those pages. Unless those pages have value, or aren’t linked to anywhere else in the site, we recommend adding the nofollow attribute, too.
The complete code will look like this:

Conclusion
Keyword cannibalisation is an extremely common, yet often overlooked issue that can plague your sites. As we mentioned, it’s often unintentional and normally the result of not accommodating for content growth.
Fear not, it can be resolved and rankings/traffic/conversions will return to their former positions with relative ease once you’ve eliminated the issue.
As with anything in SEO, it’s about finding the balance between users and crawlers. For the sake of your sanity, we always recommend testing before scaling.
Stay in touch with the Zazzle Media family
Sign up for our monthly newsletter and follow us on social media for the latest news.



